
Decisiones automatizadas, profiling, Inteligencia artificial ¿Qué son?
En este post hablaremos de la Guía de la Agencia Española de Protección de Datos sobre Inteligencia Artificial, pero sobre todo, trataremos de explicar con ejemplos las diferencias entre los conceptos de decisiones automatizadas en general, profiling y el ámbito del art. 22 RGPD. También habrá algo sobre la anonimización, el big data, el horóscopo, las bases de legitimación aplicables a todo esto y otras hierbas.
Indice
- La guía de la Agencia
- ¿De qué hablamos cuando hablamos de profiling? ¿en qué se diferencia el profiling de las decisiones automatizadas del art. 22?
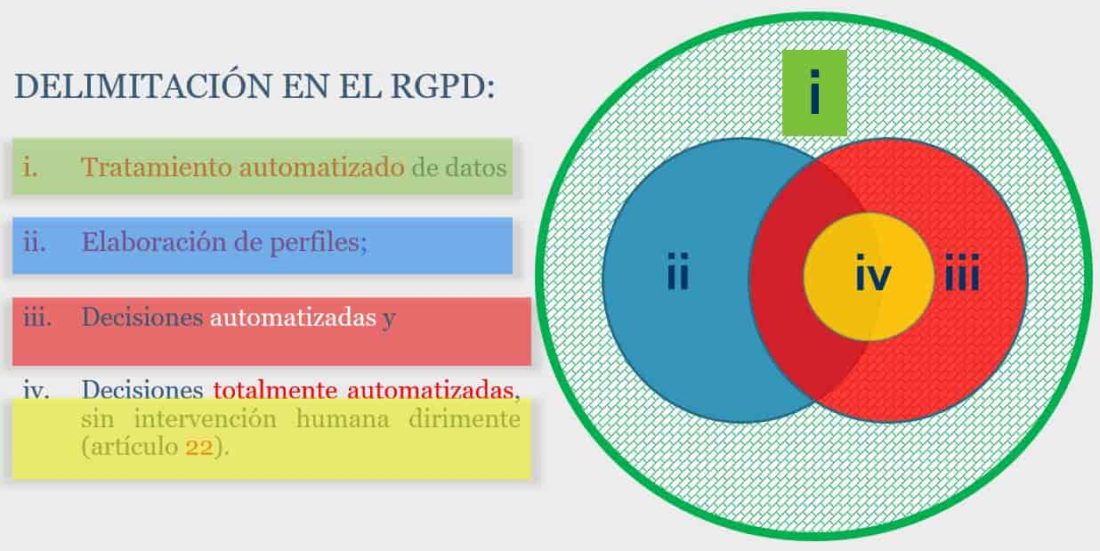
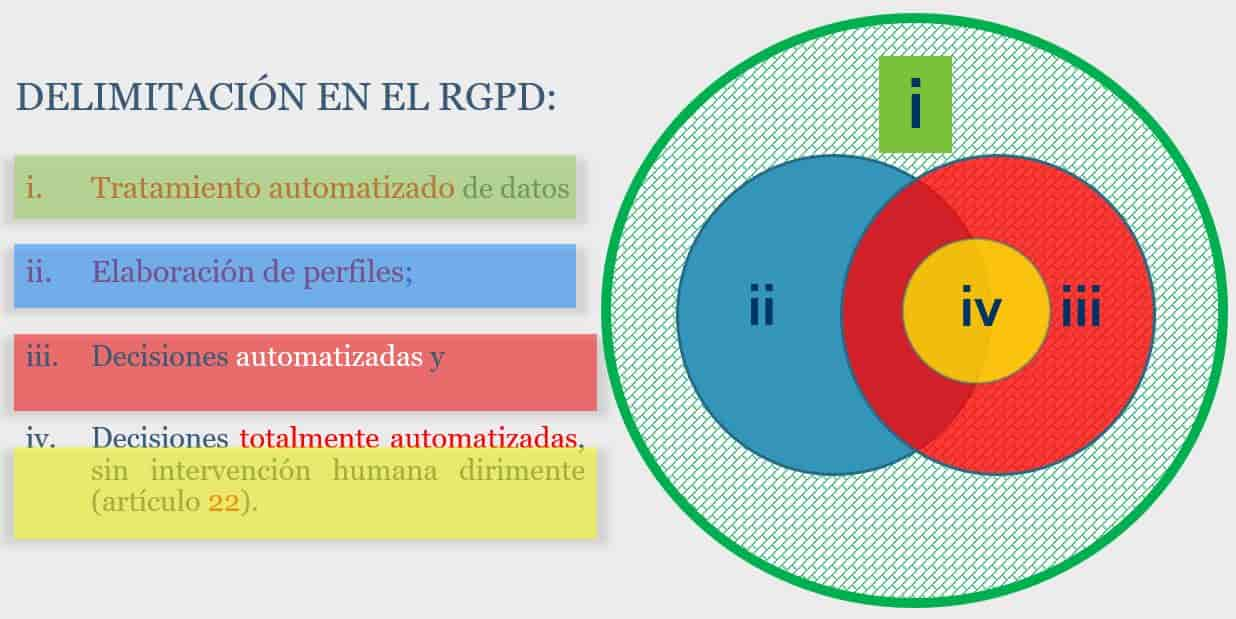
- A.- Tratamiento automatizado de datos personales
- B.- Elaboración de perfiles o “profiling” (en el sentido del RGPD)
- C.- Procesos de decisión completamente automatizados del art 22 del RGPD.
- Vale, y entonces, ¿qué hacemos?
- I.- Primera fase: Análisis de la información
- II.- Segunda fase: Aplicación de modelos predictivos o de las conclusiones de la primera fase
- Bases legítimas de tratamiento aplicables a decisiones automatizadas
- Otras cosillas
La guía de la Agencia
La semana pasada la AEPD publicó su Guía sobre adecuación al RGPD de tratamientos que incorporan Inteligencia Artificial.
El planteamiento de la Agencia es muy bueno: la materia tiene tantas ramificaciones y tan profundas que es imposible abarcarlo todo en un solo documento. Por eso, creo que esta guía persigue exponer sistemáticamente y de forma comprensible para ambos mundos, las cuestiones que tecnólogos y juristas deben saber trabajar y resolver conjuntamente.
Además llega en el momento adecuado, con la paralización judicial del sistema automatizado antifraude utilizado por la Seguridad Social holandesa, por sesgos en la aplicación de la tecnología y abusiva alegación de secreto empresarial para justificar la nula transparencia del funcionamiento del sistema: no vale encogerse de hombros y echar la culpa al desarrollador.
No sirve lo de “la culpa para el Maestro Armero” en este ámbito. Los sistemas que utilizas para automatizar tu trabajo son responsabilidad tuya.
Aplaudo las referencias a conceptos innovadores como los de privacidad diferencial o encriptación homomórfica. Está muy bien que la Agencia apunte que existen (estas y otras) técnicas para hacer las cosas bien: de forma responsable y transparente.

¿De qué hablamos cuando hablamos de profiling? ¿en qué se diferencia el profiling de las decisiones automatizadas del art. 22?
El concepto de perfilado o “profiling” se entiende mejor contraponiéndolo a otros con los que se suele confundir.
Lo importante, creo yo, es no perder de vista que estas cosas funcionan como el horóscopo.
Sip. El horóscopo.
Todos sabemos cómo «funciona»: clasifica a la gente en categorías a las que asigna unas características comunes, de modo que si eres Capricornio, da igual exactamente cómo seas de verdad: con base en un “estudio astrológico” he determinado que todos los capricornios sois ingeniosos, inteligentes y cordiales. Por ejemplo.
Lo que intento decir es que tanto el profiling como los procedimientos de decisión automatizadas más o menos avanzados, ofrecen predicciones o valoraciones para una persona, sabiendo poco o mucho de ella, pero sin tener en cuenta a la persona en sí, sino su pertenencia a grupos de personas como ella (en función de los datos de los grupos que se han estudiado previamente).
Huelga decir que es un terreno abonado para el error. La cuestión es que los humanos que estaban al cargo de casi todo hasta ahora, también se equivocan. De modo que, en la medida en que los algoritmos prueben ser, no perfectos, sino sólo algo mejores que los humanos… los vamos a ver hasta en la sopa.
Muchísimas cosas se podrán automatizar con aceptables márgenes de error y las GPUs siguen subiendo en potencia y bajando en precio, así que… here we go.
Pero es un tema lioso: para que se entienda mejor, trataré de explicar los conceptos en orden creciente de complejidad, utilizando siempre los mismos ejemplos.
A.- Tratamiento automatizado de datos personales
El RGPD se aplica al “tratamiento total o parcialmente automatizado de datos personales, así como al tratamiento no automatizado de datos personales contenidos o destinados a ser incluidos en un fichero”.
Pero obviamente, no cualquier tratamiento automatizado de datos personales implica que se estén elaborando perfiles.
Por ejemplo:
- La recogida de datos de sexo y medidas físicas (talla) de trabajadores para alimentar un software que ayude a gestionar la entrega de material de trabajo a los empleados (botas, equipamiento de protección), es tratamiento automatizado de datos, pero no tiene por qué ser profiling, como veremos de inmediato.
- Las cámaras de fotos que imponen multas por exceso de velocidad (tratamiento automatizado de dato personal: matrícula del coche).
B.- Elaboración de perfiles o “profiling” (en el sentido del RGPD)
La elaboración de perfiles o profiling está formada por tres elementos:
- Implica un tratamiento automatizado de datos;
- de datos personales; y
- la finalidad de la elaboración de perfiles debe ser evaluar aspectos personales sobre una persona física.
En los ejemplos anteriores, existiría profiling:
- Si los datos que se tratan para adjudicar los enseres y medios de protección a los trabajadores, se cargaran en la plataforma informática utilizada por RRHH (tratamiento automatizado) y se tuvieran en consideración también para determinar, tomando en cuenta la función o categoría profesional del trabajador, la rentabilidad o productividad de los mismos –presente y futura- (con impacto, por ejemplo, en su sueldo o carrera profesional).
- Si el histórico de multas (o simplemente de velocidades observadas) se registrara en el perfil del conductor, en un archivo personalizado de la DGT, que se utilizara para campañas de sensibilización de seguridad vial, o para endurecer las sanciones por reincidencia o malos hábitos de conducción.

C.- Procesos de decisión completamente automatizados del art 22 del RGPD.
El artículo 22 se aplica exclusivamente a aquellas decisiones totalmente automatizadas (decisiones adoptadas y ejecutadas sin intervención humana dirimente) con efectos jurídicos o que afecten significativamente de modo similar a los titulares de los datos tratados:
- Efectos jurídicos para el interesado, es decir que afecte a sus derechos o a su esfera jurídica, como, por ejemplo, la denegación de subvenciones públicas, de entrada a un país, o la cancelación de un contrato o
- Le afecte significativamente de modo similar, es decir que produzcan una consecuencia tan relevante para el interesado como la jurídica.
Se citan como ejemplos en las guidelines del EDPB, la desestimación en un proceso de selección, la denegación de un crédito o seguro, o la aplicación de precios distintos a un mismo colectivo. No es necesario que afecte a un gran número de personas
En los ejemplos anteriores, aplicaría el art 22 RGPD:
- Si, atendiendo a (i) las condiciones del trabajador (p.ej: sexo, talla, curriculum, capacitación) y (ii) al histórico de productividad, rotación profesional, y éxitos y fracasos anteriores en la empresa de perfiles parecidos, se les adjudicara tal o cual función mediante una decisión automática, sin supervisión humana capaz de modificarla.
- Si el sistema de cámaras fuera capaz de activar el envío automático de una sanción personalizada con base en el histórico de sanciones, comportamiento del infractor previo a la acción sancionada, antigüedad del vehículo, velocidad media del resto de los conductores en ese momento, etc…
Otros ejemplos serían:
- Las tristemente famosas “paralelas” -liquidaciones complementarias remitidas por la Agencia Tributaria- cuando, p. ej. no coinciden las partidas de IVA repercutidas y soportadas, declaradas por profesionales liberales o autónomos que han contratado entre sí.
- Las tarjetas de crédito preconcedidas que envían las entidades financieras al domicilio de sus clientes (sin que hayan sido solicitadas) al detectar que el cliente tiene capacidad crediticia “sin utilizar”.
- El scoring automatizado que en los últimos tiempos se está implantando y puede condicionar, atendiendo por ejemplo a los comentarios de los ciudadanos en sus redes sociales, que se pueda conceder o denegar el visado o el acceso en la frontera de un determinado país.
De acuerdo con lo anterior, vemos que la casuística puede ser muy diversa:
- Cabe tratamiento automatizado de datos sin elaboración de perfiles
- Elaboración de perfiles como apoyo a procesos de decisión automatizada
- Elaboración de perfiles como base de procesos de decisión completamente automatizada
- Procesos de decisión automatizada con o sin elaboración de perfiles previa.
Vale, y entonces, ¿qué hacemos?
Para que este texto no resulte tan indigesto como la guía de la Agencia, voy a referirme a todos estos procesos en general como “big data”. Sé que no es correcto, pero… EH! En mi blog escribo lo que quiero: apedréenme!!
El “big data” opera en dos escenarios claramente distinguibles (sí son más, pero… lo de antes):
- Una fase de análisis en la que el dato personal no es relevante, y
- Una segunda fase de aplicación a personas físicas concretas.
I.- Primera fase: Análisis de la información
El análisis de un conjunto de datos o “data set” consiste sustancialmente en la comparación de los datos, las circunstancias, características “observables” para tratar de obtener patrones, inferencias (datos “nuevos” que “no eran observables”).
Y esto se realizará, dependiendo de las capacidades del responsable, con un análisis más o menos manual, o utilizando “minería de datos”, es decir aplicando algoritmos al data set. Incluso “machine learning”, si esos algoritmos son capaces de aprender por sí mismos, reformulando su forma de actuar para alcanzar su objetivo.
Esta primera fase suele incluir dos subfases: una previa al aprendizaje:
1. Anonimización o seudonimización.
En la fase de análisis los datos conocer la concreta identidad de los titulares no interesa: el interés se centra en la comparación cruzada de conjuntos de datos personales más o menos completos o estructurados, dependiendo del objetivo, para obtener patrones con base en las circunstancias concurrentes en cada caso.
A estos efectos es importante no confundir dos conceptos:
Anonimización: A los datos anónimos (que no permiten reidentificar a su titular/es original/es) no se les aplica la normativa de protección de datos personales. Así se explica en el Considerando 26 del RGPD:
“los principios de protección de datos no deben aplicarse a la información anónima, es decir información que no guarda relación con una persona física identificada o identificable, ni a los datos convertidos en anónimos de forma que el interesado no sea identificable, o deje de serlo”.
La seudonimización, en cambio, consiste en reemplazar un atributo de un set de datos (normalmente uno que funcione como identificador único, como puedan ser “nombre y apellidos”, “NIF”, “Número de la Seguridad Social”, “Teléfono móvil” por otro atributo que no sea público, o directamente por un código aleatorio generado para la ocasión (por ejemplo, el “Apple ID”) que no permita reconstruir el identificador original.
Lo que interesa que quede claro es que, en la medida en que exista una tabla de correlación (que permita vincular los datos seudonimizados con su titular) en el ámbito del responsable (o de alguno de los corresponsables) del tratamiento los datos seudonimizados siguen siendo datos personales, con la obligación de cumplir todas las obligaciones y garantías impuestas por la normativa.
En este sentido el Considerando 28 del RGPD subraya que “la introducción explícita de la «seudonimización» en el presente Reglamento no pretende excluir ninguna otra medida relativa a la protección de los datos”.
Por tanto, la seudonimización es una medida de seguridad muy potente y recomendable, pero no evita la aplicación de la normativa analizada.
Además, se debe señalar que, aunque existen tecnologías novedosas como la encriptación homomórfica (que permite replicar data sets en un “clon” encriptado y anonimizado que permite sustancialmente las mismas operaciones y análisis que el original), el “mantra” actual es que la anonimización irreversible es inalcanzable, y ello porque (i) cuando el data set es suficientemente rico, los propios datos serán capaces de identificar a su titular, y (ii) porque los avances tecnológicos permiten ataques de reidentificación cada vez más complejos, y audaces.
Adicionalmente, la mera anonimización es un tratamiento de datos que requiere ser legitimado e informado al titular de datos personales.
Por ello, es necesario informar a los interesados acerca de la intención de analizar la información y definir los fines últimos a que obedecerán los proyectos de uso de la información analizada.

2. Reevaluación:
Consiste en la revisión de los patrones e inferencias detectados mediante, p.ej., filtrados o estudios técnicos (p.ej. depurando errores, o contingencias en el dataset, el estudio o los resultados), lógicos (desestimando meras correlaciones sin sentido o valor, diferentes de inferencias o causalidades extrapolables con utilidad fuera del dataset inicial) y jurídicos (detectando sesgos –que pueden estar en el dataset, en la mera técnica de estudio o en los resultados- que pongan en peligro tanto la propia utilidad de las inferencias, como los derechos de las personas sobre las que se apliquen los resultados).
Como consecuencia de una revisión eficaz, los resultados o conclusiones permitirán obtener modelos predictivos útiles, aplicables a nuevos sujetos.
Los actuales proyectos de perfilado avanzado se caracterizan por permanecer en estado de desarrollo y mejora permanente: mediante técnicas de analítica e interpretación profunda de datos se pretende la optimización en el diseño y prestación de servicios. Persiguen alcanzar modelos predictivos que permitan el diseño e implementación de servicios cada vez más personalizados y que al mismo tiempo se puedan prestar con mayor eficacia y eficiencia.
II.- Segunda fase: Aplicación de modelos predictivos o de las conclusiones de la primera fase
En esta segunda fase se aplican a casos concretos las inferencias y conclusiones obtenidas en la primera fase para permitir adoptar la decisión oportuna en relación con sujetos nuevos, con características homogéneas, y esta vez sí, determinados.
A diferencia del análisis en la primera fase, esta segunda tratará ya datos personales concretos, no seudonimizados.
La incidencia en la privacidad del individuo es más intensa que en la primera, ya que la aplicación de las conclusiones obtenidas en la fase de análisis afecta directamente a los intereses y derechos de los individuos sujetos a los efectos de la aplicación de las conclusiones obtenidas de la fase previa.
Es en esta segunda fase cuando aplicará o no el régimen especial del art 22 RGPD, dependiendo de si el conocimiento adquirido en la fase de análisis se traduce en la implementación de procesos de decisión completamente automatizada (decisiones automáticas) o no con “efectos jurídicos relevantes” para los titulares.
Bases legítimas de tratamiento aplicables a decisiones automatizadas
Como bien dice la Guía de la Agencia, cada fase (y subfase) admite bases legítimas de tratamiento distintas, y aquí está la madre del cordero.
Este tema lógicamente es inacabable, así que cerramos el post con unas pinceladas:
En la primera fase de entrenamiento, minipunto para la Agencia por explicitar que el interés legítimo es la que “reclama del responsable un mayor grado de compromiso, formalidad y competencia”, porque es la pura verdad. Al menos en la teoría, claro. Porque en la práctica, muchas empresas amparan en esta base sus proyectos sin hacer una ponderación mínimamente decente ni informar a los interesados.
Hablando ya de sistemas en explotación, la guía destaca que para que el consentimiento del interesado pueda ser considerado “libre”, al solicitarlo se le deben proporcionar “alternativas viables y equivalentes” a la decisión automatizada.
Evidentemente, esto no es lo común.
Peor aún: proliferan en las políticas de privacidad referencias vergonzantes a la base contractual para estos menesteres, ignorando que (i) el contrato tiene que vincular precisamente a responsable e interesado y (ii) el tratamiento tiene que ser indispensable para el cumplimiento del contrato. Ambas condiciones tienen que darse conjuntamente -y sin datos de categoría especial por medio- para legitimar tratamientos del art 22. Mas sobre esto por aquí.
Otra mala práctica extendida es la de estirar como un chicle el concepto de “investigación científica” pretendiendo ampararse en su régimen especial. La guía trata el tema de pasada. La Opinión del EDPS de enero pasado tiene mucho que decir sobre, entre otras cosas, qué es y qué no “investigación” a estos efectos.

Otras cosillas
Por último, la guía apunta cuestiones de plena actualidad en otros ámbitos, pero que tienen especial relevancia en tecnologías que potencialmente pueden afectar (afectan ya) a toda la ciudadanía:
1.- La necesidad de cumplir los siete principios del art. 5 del RGPD en todas las fases del tratamiento, con independencia de la base de legitimación elegida. Algo especialmente relevante en este ámbito, muy poco regulado.
2.- La corresponsabilidad, también ubicua en este ámbito, explicada por etapas en el workflow y por roles que pueden desempeñar los implicados: Una empresa puede perfectamente ser (cor)responsable de tratamiento aunque no tenga acceso alguno a datos personales o aunque no conozca ni pueda (ni quiera) conocer cómo funciona exactamente la “flamante IA” que han comprado o contratado. Recordad lo del Maestro Armero.
3.- Ejemplos “cotidianos” de IA: La sentencia “Fashion Id” nos ha enseñado algo sobre la corresponsabilidad de quien inserta en su web un algo aparentemente inofensivo, sin saber exactamente cómo funciona y de qué es capaz. Y la guía menciona explícitamente un ejemplo tan “tonto” como los “recaptcha” que para cumplir su función identifican usuarios.
No miro a nadie, Google. Ni a ti si lo tienes en tu web.
Buen carnaval a todos.
Jorge García Herrero
Abogado y Delegado de Protección de Datos
Imágenes: creación propia, y de Stephen Dawson Markus Spiske Curtis MacNewton, David Werbrouck encontradas en Unsplash